Exploring Edge AI on Altera Agilex 3 FPGAs with OneWare Studio
October 11, 2025
Intro
At the end of September, I attended Arrow Electronics workshop here in Portland, Oregon. Hosted together with Altera (yep it's back) and OneWare, it focused on the Altera Agilex 3 FPGA. There's a ton of hands-on labs in the workshop, but most interesting to me were the ones focusing on building and deploying machine learning models and performing inference on FPGAs. Or to use the latest buzzword - Edge AI.
As of the time of writing this article the workshop is still ongoing. See here for all the dates and locations. If you are interested in modern FPGAs, machine learning or Edge AI and have a chance to attend I highly recommend it.
In this post I’ll share the highlights of the workshop, what stood out to me, and why I think FPGA platforms are worth paying attention to. Big thanks to the teams at Arrow, Altera, and One Ware for putting together such a great event.
Workshop Overview
It makes sense to start with short discussion of Agilex 3 FPGAs and what's interesting about them. It occupies entry or mid-range end of current Altera lineup. Last time I dealt with FPGAs was at the time when Cyclone V was on that spot, so it makes sense (at least to me) to compares these.
If you simply compare the gate count then Agilex 3 is comparable to Cyclone V (25K - 135K LEs). But performance wise it uses new fabric architecture, should be less power hungry (I saw 38% being mentioned) and has a bunch of newer and faster interfaces on board. It's quite a bit more expensive too. Also, there's a significant difference between lower end Agilex 3 and higher end models in terms of transceivers and hard IPs on board.
Couple of things about why Agilex 3 is particularly interesting FPGA for Edge AI applications:
DSP blocks optimized for AI workloads
AI tensor blocks supporting tensor dot products of 10-element INT8 vectors. Half-precision 16-bit arithmetic FP16 and FP19 floating point modes, and support for BFLOAT16 floating point format.
For INT8 operations in a single DSP block, the Agilex™ 3 FPGAs and SoCs C-Series improve peak theoretical TOPS up to 5.1 times than Cyclone® V FPGAs
-Altera
Low power envelope
Allows to create custom AI pipelines that optimize performance within a strict power budget. Power-efficient AI inference.
Reconfigurability
Allows implementing custom accelerators tailored to a specific neural network or dataflow. This is especially interesting in the context of using software that simplifies and speeds up model deployment.
Agilex 3 focuses on low-power, mid-density designs that can still implement compact neural network inference engines. I think it will fit well in applications from smart sensors and machine vision to industrial control.
All labs in the workshop target same development board - AXC3000. It's a nice and compact board powered by USB-C connector (also used for Virtual Com Port and JTAG). While the small size is great, it does come with a trade-off - the board doesn't accommodate any standard physical connectors and instead exposes a single CRUVI HS connector. So if you want to work with any FFC cable (MIPI, LCD etc.), Ethernet PHY, HDMI or anything really - you need to buy or design an adapter. You can see full board specs following the link, but here's a short summary:
- FPGA: Agilex® 3 (A3CY100BM16AE7S)
- ≈100K LE
- LPDDR4
- MIPI D-PHY
- PCIe Gen3
- 10Gb Ethernet
- Memory:
- HyperRAM — 128 Mbit
- QSPI Flash — 256 Mbit
- Sensors: 3-axis accelerometer
- Indicators: RGB LED
- Utilities: On-board Programmer / Debugger
The Lab
The Agilex 3 workshop consists of around 8 labs covering different topics from LED blinky to timing closure, NIOS V soft core and finally AI applications. Even though the workshop is full-day, it's unrealistic to complete more than couple of those labs during the hours. So I concentrated on the first one (the good old blinky) to verify the process and the hardware and then moved to more interesting ones. There's 2 AI related labs - Altera's FPGA AI suite and OneWare. Since it's realistic to complete only one, I went with OneWare ONE AI lab.
Here I'll summarize the main ideas of the lab. The full training materials are available on Github.
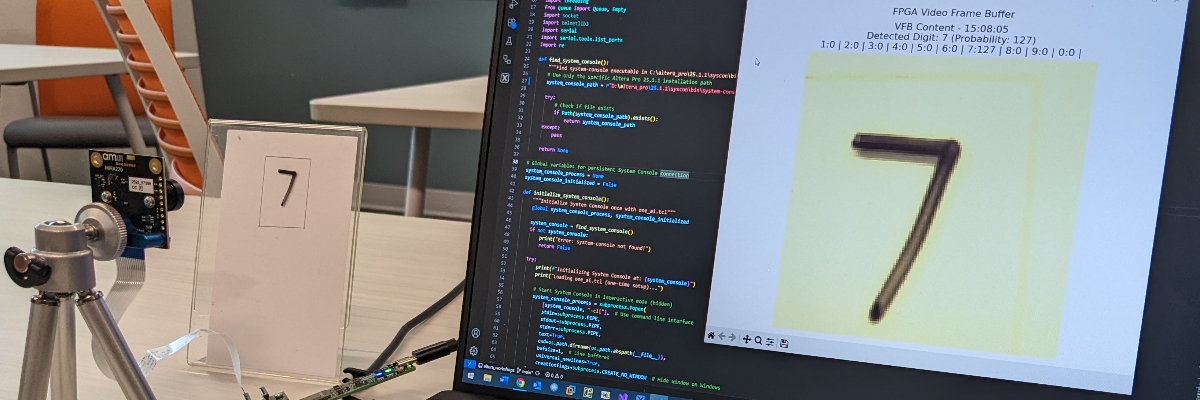
The goal of the lab was to build a MNIST classifier model based on CNN (Convolutional Neural Network) architecture. The MNIST dataset is a classic benchmark of 70,000 handwritten digit images (0–9), widely used to test and demonstrate machine learning and computer vision models. Within the lab we only used a subset of MNIST to make things simpler. Then using OneWare software you would train and synthesize the model into VHDL, deploy it on Agilex 3 and use OSRAM Mira220 camera module to perform real-time recognition of hand-written digits.
The overall workflow of the workshop could be summarized as follows:
- Prepare dataset
- Configure machine learning model
- Train the model
- Export the model
- Deploy the model into FPGA
- Test on AXC 3000 board
First 4 steps above were simplified using OneWare ONE AI software. ONE WARE's ONE AI is a software platform that automates the creation of custom AI models tailored for specific hardware and applications, including FPGAs:
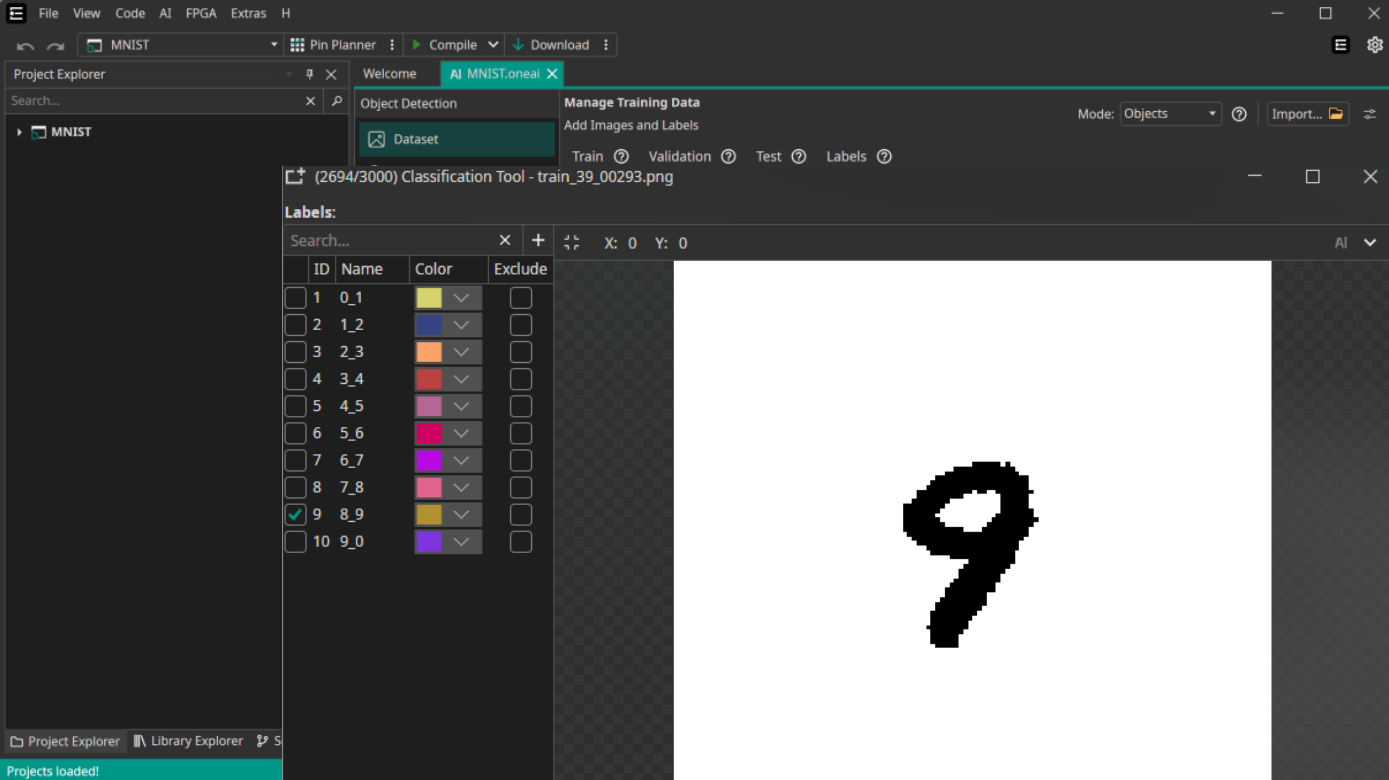
Figure 1. OneWare Software UI
The dataset was provided as part of the lab. Next step was to upload it into OneWare Studio and begin preparation for training. First the data would need to be augmented to improve generalization and achieve higher accuracy at the end. Augmentations consist of different translation options, noise and color transformations.
The software provides a lot of options for different pre- and post- augmentation filters, such as threshold, low and high pass frequency filters etc. There's rich set of user-friendly GUI settings that allow to configure model parameters such as number of features, same-class variation or memory usage. Finally you set parameters of the device including the family (in our case Altera Agilex 3) and this step is done.
Now we need to train the model. OneWare is a cloud software so the actual training happens on their servers. Here, of course, comes their business model where you need to spend "credits" to buy compute to train your model. As part of the lab I was provided with some free credits and so the training began. I won't dive into details here, there's a lot of subtleties in the process of which you can read in the lab materials. But if all goes well, after some minutes the model should be ready for export.
OneWare supports exporting models into various formats like ONNX, TensorFlow or in our case - VHDL. Once you export the VHDL IP from OneWare the hard part would be to add it into overall system. Luckily the lab project was pre-populated with with most of the IP required to created finished system. I just had to use Quartus Platform Designer to tie everything together. The design includes components such as the JTAG Master, PIO, MIPI system, NIOS V (soft-core processor based on RISC-V), and more. Full structural diagram can be seen below:

 Figure 2. System Structure (adapted from Arrow Training Materials)
Figure 2. System Structure (adapted from Arrow Training Materials)
Once Quartus project was compiled the last step was to build NIOS V BSP and firmware. This is required to initialize the camera hardware, read camera data as well as query the inference result from ONE AI IP block, among other things. This was done using Ashling RiscFree IDE and resulting .hex was added as part of FPGA bitstream. It will be programmed in memory and executed by
NIOS V upon boot.
The final outcome of all these steps is a fully functional MNIST classifier in action:

Figure 3. Live inference running on AXC3000 development board
Conclusion
The workshop clearly demonstrated ML workloads implemented directly on FPGA fabric, achieving low latency and high power efficiency. Seeing why Altera positions Agilex 3 as a practical edge AI platform makes a lot of sense now.
For me, the most interesting part was seeing how modern tooling like ONE AI can drastically simplify deployment on ML models on FPGA. Once again huge thanks to folks at Arrow, Altera and OneWare!
I’ll be exploring more edge AI related projects in the coming months. It would be really interesting to see how FPGA based inference compares to the ARM NPUs currently on the market. Another interesting topic would be embedded Linux + FPGA hybrid systems which you can build on higher-end Agilex 3 with double ARM Cortex A-55 hard processor cores.
👉 If you’d like to dive deeper, the original workshop materials are available on Github.